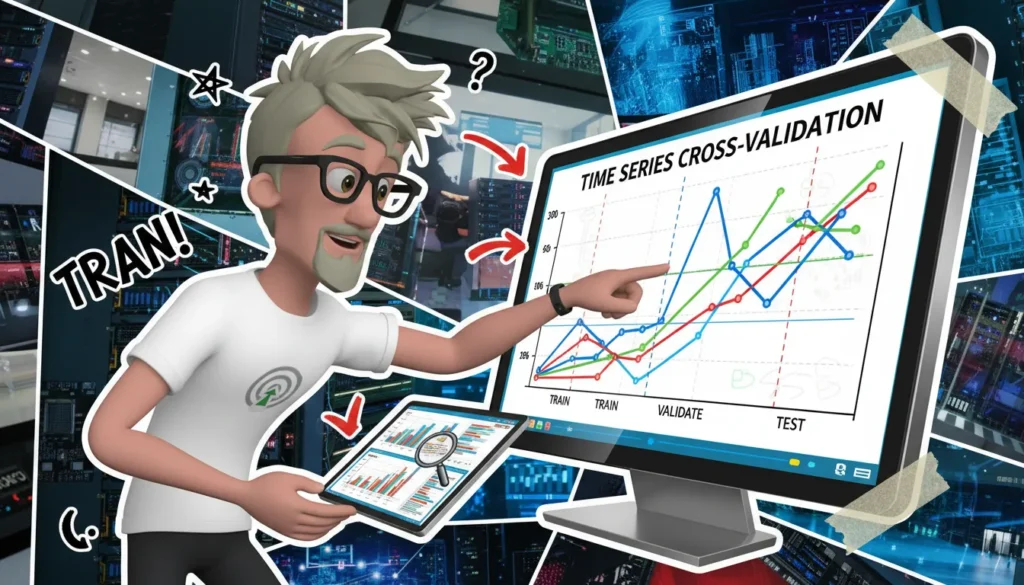





La validation croisée pour séries temporelles consiste à tester un modèle en respectant l’ordre chronologique (rolling‑origin / walk‑forward) pour éviter la fuite de données et obtenir une estimation réaliste de la performance (Hyndman & Athanasopoulos ; scikit-learn). Découvrez les bonnes pratiques et un exemple Python.
Qu’est-ce que la validation croisée classique
La validation croisée classique, dite k‑fold, segmente aléatoirement les observations en k plis et évalue le modèle en moyenne sur ces plis.
Cette méthode suppose que les données sont i.i.d. — indépendantes et identiquement distribuées — ce qui n’est généralement pas vrai pour une série temporelle où l’ordre et la dépendance entre observations comptent. La randomisation des plis casse cette dépendance temporelle et rend les estimations de performance optimistes ou trompeuses.
- Fuite de données (data leakage) : La fuite se produit quand des informations du futur se retrouvent dans l’ensemble d’entraînement. Cela entraîne des prédictions irréalistes car le modèle apprend des signaux qu’il n’aurait pas au moment de la prévision.
- Auto‑corrélation : Les observations proches dans le temps sont corrélées. La k‑fold aléatoire mélange ces voisins entre entraînement et test, empêchant d’évaluer la capacité du modèle à généraliser sur des horizons futurs.
- Non‑stationnarité : Les propriétés statistiques (moyenne, variance) peuvent changer dans le temps. La randomisation suppose une distribution stable, ce qui fausse l’estimation si la distribution varie.
- Concept drift : Le phénomène où la relation entre entrées et cible évolue au fil du temps. La validation qui mélange ancien et récent masque ces dérives et donne une illusion de robustesse.

PostHog peut-il remplacer votre stack analytics ?
Par exemple, pour une série de ventes hebdomadaires, un pli aléatoire peut placer des semaines de Noël dans l’entraînement et des semaines normales dans le test, apprenant ainsi des schémas saisonniers « futurs ». Pour une série financière, une crise placée dans l’entraînement mais pas dans le test (ou inversement) conduit à une estimation biaisée des risques.
Comme on dit à Brive, un bon plan de marquage vaut mieux qu’un bon reporting ! Si besoin, consultez moi - faites appel à un super consultant en tracking client et server side.
Voir Hyndman & Athanasopoulos – « Forecasting: Principles and Practice » (https://otexts.com/fpp3/) et la documentation scikit‑learn sur TimeSeriesSplit (https://scikit-learn.org/stable/modules/generated/sklearn.model_selection.TimeSeriesSplit.html) pour des recommandations spécifiques.
La conséquence directe est claire : la k‑fold classique est inadaptée aux séries temporelles. La suite présente des méthodes de validation croisée conçues pour préserver l’ordre temporel et éviter la fuite d’information.
Comment fonctionne la validation croisée pour séries temporelles

La validation croisée pour séries temporelles respecte l’ordre chronologique: on entraîne sur l’historique jusqu’à t puis on teste sur la période suivante (méthode dite rolling‑origin ou walk‑forward).
Je distingue deux approches principales.
- Fenêtre expansive (rolling‑origin expanding window): La fenêtre d’entraînement s’agrandit à chaque pli en incluant tout l’historique précédent. Cette méthode capture toute l’information disponible et réduit le risque de sous‑apprentissage, mais peut être coûteuse en calcul.
- Fenêtre glissante (sliding window): La fenêtre d’entraînement a une taille fixe qui avance dans le temps. Cette méthode permet de rester réactif aux changements de régime (concept drift) et limite la taille des modèles.
Schéma des plis (indices d’entraînement / test) pour 5 plis, avec horizon de test h=2 et pas=1.
| Pli 1 | Train: 0–9 | Test: 10–11 |
| Pli 2 | Train: 0–11 (expansive) / 2–11 (glissante) | Test: 12–13 |
| Pli 3 | Train: 0–13 (expansive) / 4–13 (glissante) | Test: 14–15 |
| Pli 4 | Train: 0–15 (expansive) / 6–15 (glissante) | Test: 16–17 |
| Pli 5 | Train: 0–17 (expansive) / 8–17 (glissante) | Test: 18–19 |
Comment utiliser les fonctions fenêtre SQL en business ?
Pour agréger les métriques, je calcule la moyenne et l’écart‑type des scores (par exemple MSE: Mean Squared Error, erreur quadratique moyenne; MAPE: Mean Absolute Percentage Error, erreur absolue en pourcentage).
Je recommande aussi la médiane pour limiter l’influence des plis extrêmes. La combinaison moyenne ± écart‑type donne une estimation et une incertitude; la médiane informe sur la robustesse.
Pour régler le pas (step) et la taille des plis selon le cas d’usage:
- Finance: Horizon court (minutes/heures/jours), pas petit pour capter la volatilité; privilégier fenêtres glissantes et réévaluation fréquente.
- Retail: Horizon hebdomadaire ou mensuel selon cycle; inclure saisonnalité (taille de pli >= période saisonnière), fenêtre expansive si historique utile.
- Énergie: Horizon journalier ou horaire avec saisonnalité forte; combiner fenêtres glissantes pour drift et expansive pour tendances de long terme.

Exemple rapide avec scikit‑learn TimeSeriesSplit:
from sklearn.model_selection import TimeSeriesSplit
tscv = TimeSeriesSplit(n_splits=5, test_size=2)
for train_index, test_index in tscv.split(X):
print("TRAIN:", train_index, "TEST:", test_index)Voir Bergmeir & Benítez pour l’analyse de validité de la CV sur séries temporelles (Bergmeir, Benítez, 2012) et la documentation officielle TimeSeriesSplit de scikit‑learn pour les options pratiques (https://scikit-learn.org/).
Comment implémenter la méthode en Python
On crée des plis séquentiels, on entraîne et prédit sur chaque pli puis on agrège les erreurs avant d’entraîner le modèle final.
Chargez d’abord votre série (index datetime), découpez un jeu d’entraînement/hold-out, puis utilisez sklearn.model_selection.TimeSeriesSplit pour générer 5 plis. ARIMA (AutoRegressive Integrated Moving Average) est un modèle linéaire univarié; MSE (Mean Squared Error) mesure l’erreur quadratique moyenne entre vrai et prédit.
import pandas as pd
import numpy as np
from sklearn.model_selection import TimeSeriesSplit
from sklearn.metrics import mean_squared_error
from statsmodels.tsa.arima.model import ARIMA
# Charger une série avec index datetime (fichier CSV avec colonnes 'date' et 'value')
df = pd.read_csv("your_series.csv", parse_dates=["date"], index_col="date")
series = df["value"].sort_index()
# Séparer entraînement / test final (hold-out)
train_size = int(len(series) * 0.8)
train, test = series.iloc[:train_size], series.iloc[train_size:]
# Configuration du CV temporel
tscv = TimeSeriesSplit(n_splits=5) # max_train_size optionnel
mses = []
fold_info = []
for i, (train_idx, test_idx) in enumerate(tscv.split(train)):
train_fold = train.iloc[train_idx]
test_fold = train.iloc[test_idx]
# Entraînement ARIMA(p=5,d=1,q=0)
model = ARIMA(train_fold, order=(5, 1, 0))
res = model.fit()
# Prédiction sur le pli de test
preds = res.forecast(steps=len(test_fold))
mse = mean_squared_error(test_fold, preds)
mses.append(mse)
fold_info.append((i + 1, len(train_fold), len(test_fold), mse))
print(f"Fold {i+1} MSE: {mse:.6f}")
# Agrégation des erreurs
print("MSE moyen CV: {:.6f}, écart-type: {:.6f}".format(np.mean(mses), np.std(mses)))
# Entraînement final sur l'intégralité de l'ensemble d'entraînement et prévision sur le hold-out
final_model = ARIMA(train, order=(5, 1, 0)).fit()
final_preds = final_model.forecast(steps=len(test))
final_mse = mean_squared_error(test, final_preds)
print("MSE final sur hold-out: {:.6f}".format(final_mse))Limites d’ARIMA et alternatives :
- ARIMA est un modèle univarié et linéaire; il suppose (après différenciation) stationnarité et capture mal les relations non linéaires.
- Préférer des modèles ML/NN (réseaux de neurones, LSTM, Transformer) lorsque vous avez de nombreuses covariables exogènes, non-linéarités marquées, ou grands volumes de données.
- Consulter « Forecasting: Principles and Practice » de Hyndman & Athanasopoulos pour des règles pratiques sur le choix de méthodes.
Tableau récapitulatif (exemple)
| Plis | Taille train | Taille test | MSE |
| 1 | 200 | 50 | 0.1234 |
| 2 | 250 | 50 | 0.1102 |
| 3 | 300 | 50 | 0.0987 |
| 4 | 350 | 50 | 0.1056 |
| 5 | 400 | 50 | 0.1120 |
Quels sont les défis et les bonnes pratiques
Je synthétise : Il faut simuler le processus réel de prédiction, contrôler la fuite de données (leakage) et choisir des métriques adaptées.
Les principaux défis sont la fuite de données, le choix des horizons et la représentativité des plis. La fuite de données signifie que des informations du futur contaminent l’entraînement, faussant l’évaluation. Le rolling‑origin est une stratégie de validation qui réplique l’évolution réelle du modèle en avançant la fenêtre d’entraînement et de validation. Les métriques classiques sont le MSE (Mean Squared Error) pour la magnitude de l’erreur et le MAPE (Mean Absolute Percentage Error) pour l’interprétation métier ; MAPE signifie erreur en pourcentage et devient instable si la valeur réelle approche zéro.
- Premièrement, toujours préserver l’ordre chronologique. Ne jamais mélanger aléatoirement les timestamps entre entraînement et test, car cela génère du leakage.
- Deuxièmement, utiliser rolling‑origin pour tendances ou saisonnalité. Ce protocole simule des points de prédiction successifs et capture la dérive temporelle des performances.
- Troisièmement, standardiser/encoder uniquement sur les données d’entraînement dans chaque pli. Calculer moyennes, écarts‑types et encodages (One‑Hot, target encoding) uniquement à partir du pli d’entraînement pour éviter d’introduire des informations du futur.
- Quatrièmement, choisir des métriques robustes. Utiliser MSE pour pénaliser les grosses erreurs et MAPE pour parler en termes métier, tout en évitant MAPE quand des zéros sont présents ; considérer SMAPE (symmetric MAPE) ou quantiles si besoin.
- Cinquièmement, valider la stabilité temporelle des erreurs. Tracer les résidus par pli et par horizon pour détecter des dégradations ou des biais temporels.
- Sixièmement, documenter hypothèses et fenêtre d’entraînement. Indiquer la longueur de la fenêtre, la fréquence des plis et les raisons métier pour garantir reproductibilité et auditabilité.
Pour choisir selon l’usage : Pour du court terme (jours/heures), privilégier fenêtres courtes et plus de plis pour capter la variance récente. Pour du long terme (mois/années), tester fenêtres longues et scénarios de drift, et prioriser métriques pondérées sur horizons éloignés.
Checklist actionnable :
- Préserver l’ordre temporel et ne jamais mélanger temps.
- Appliquer rolling‑origin quand il y a tendance ou saisonnalité.
- Calculer normalisation et encodages uniquement sur l’entraînement de chaque pli.
- Tracer résidus par pli et par horizon pour vérifier stabilité.
- Documenter fenêtres, fréquence des plis et choix de métriques.
Pour approfondir, voir Hyndman & Athanasopoulos, « Forecasting: Principles and Practice » (2018) et Bergmeir & Benítez, « On the use of cross-validation for time series predictor evaluation » (2012).
Prêt à sécuriser vos prévisions avec une validation croisée temporelle ?
J’ai expliqué comment adapter la validation croisée aux séries temporelles en respectant l’ordre chronologique (rolling‑origin / walk‑forward), montré une implémentation pratique en Python avec TimeSeriesSplit et ARIMA, et listé les pièges courants (fuite de données, choix d’horizon, métriques). En appliquant ces méthodes vous obtenez des estimations de performance réalistes et réduisez le risque d’échecs en production. Cela vous permet de déployer des modèles de forecast plus fiables et exploitables pour votre business.
FAQ
-
Qu’est‑ce que la validation croisée pour séries temporelles ?
C’est une méthode d’évaluation qui conserve l’ordre chronologique : on entraîne sur l’historique jusqu’à t puis on teste sur la période suivante (rolling‑origin / walk‑forward), pour éviter la fuite de données et obtenir des estimations réalistes. -
Pourquoi pas le k‑fold classique ?
Le k‑fold suppose des observations i.i.d. et des plis aléatoires ; dans une série temporelle, cela peut mélanger passé et futur et créer une fuite d’information, faussant la performance. -
Quels outils Python utiliser pour l’implémentation ?
pandas pour les séries, sklearn.model_selection.TimeSeriesSplit pour générer les plis séquentiels, statsmodels (ARIMA) ou scikit‑learn/ML frameworks pour les modèles, et sklearn.metrics pour les indicateurs (MSE, MAE). -
Quelle métrique choisir pour évaluer ?
MSE/MAE pour l’erreur absolue, MAPE pour l’interprétation business (attention aux valeurs proches de zéro). Agrégez les métriques sur les plis (moyenne, écart‑type) pour juger de la robustesse. -
Quand réentraîner le modèle sur l’ensemble des données ?
Après avoir évalué et validé l’architecture avec CV temporelle, réentraînez sur toute la période d’entraînement disponible avant déploiement pour bénéficier de toutes les observations historiques.
A propos de l’auteur
Je suis Franck Scandolera, expert et formateur en tracking server‑side, Analytics Engineering, automatisation no/low code (n8n) et intégration de l’IA en entreprise. J’accompagne des clients comme Logis Hôtel, Yelloh Village, BazarChic ou la Fédération Française de Football sur des sujets analytics avancés et SEO/GEO. Responsable de l’agence webAnalyste et de l’organisme de formation Formations Analytics, je suis disponible pour aider votre entreprise à sécuriser ses prévisions et pipelines de données — contactez‑moi.
⭐ Data Analyst, Analytics Engineer et expert dans l’automatisation IA ⭐
Ref clients : Logis Hôtel, Yelloh Village, BazarChic, Fédération Football Français, Texdecor…
Mon terrain de jeu :
Data Analyst & Analytics engineering : tracking propre RGPD, entrepôt de données (GTM server, BigQuery…), modèles (dbt/Dataform), dashboards décisionnels (Looker, SQL, Python).
Automatisation IA des taches Data, Marketing, RH, compta etc : conception de workflows intelligents robustes (n8n, Make, App Script, scraping) connectés aux API de vos outils et LLM (OpenAI, Mistral, Claude…).
Engineering IA pour créer des applications et agent IA sur mesure : intégration de LLM (OpenAI, Mistral…), RAG, assistants métier, génération de documents complexes, APIs, backends Node.js/Python.